
Neuronske mreže - aproksimatori funkcija
Sažetak
Umjetna inteligencija integrirana je u svim aspektima modernog života. Na primjer, u svijetu pametnih telefona, umjetna inteligencija omogućuje napredne funkcije kao što su prepoznavanje lica, personalizirane preporuke i optimizacija baterije. Brojne primjene nalazimo također i u drugim digitalnim uređajima, vozilima, medicini, znanosti i industriji. Neuronske mreže su jedan od alata strojnog učenja, koje je grana umjetne inteligencije i pokazuju veliku sposobnost aproksimacije funkcija, predviđanja i prepoznavanja objekata. S obzirom na veliki broj hiperparametara koji znatno utječu na uspješnost rada neuronskih mreža, njihovo treniranje može biti zahtjevan i dugotrajan proces. Znanost još uvijek nema konkretne odgovore na mnoga važna pitanja u ovom području, ali se ulažu znatni napori u njihovo istraživanje i eksperimentalno usavršavanje. U ovom radu prezentirat će se osnovna teorija neuronskih mreža i demonstrirati proces učenja neuronske mreže na primjerima funkcija u jednoj i dvije dimenzije.Ključne riječi: neuronske mreže, Tensorflow 2, aproksimacija funkcija, Python 3
1Uvod
Znanstvenici i izumitelji žele kreirati strojeve sa sposobnošću razmišljanja barem od vremena stare Grčke, čemu svjedoče i mitološke priče. Također, stotinu godina prije izlaska prvog računala, ljudi su razmatrali mogućnost da stroj postane inteligentan. U početnoj fazi nastajanja umjetne inteligencije, područje se najprije dotaklo i riješilo neke vrlo zahtjevne i teške zadatake za ljude, ali jednostavne za računala zbog postojanja strogih formalnih pravila koja opisuju takve probleme, npr. igranje šaha. IBM-ov Deep Blue sustav za igranje šaha pobijedio je Garryja Kasparova, tada svjetskog prvaka u šahu, 1997. godine. Šah je vrlo kompleksna igra iz pogleda čovjeka, ali s obzirom da se može opisati vrlo formalnim algoritmom i pravilima, računalo može igrati šah s lakoćom, predviđajući veliki broj poteza unaprijed. Zanimljivo je da unotač tome, mnoge stvari koje su ljudima jednostavne, računalnim sustavima su izrazito teške, poput prepoznavanja objekata ili glasa
Umjetna inteligencija (UI) postaje neizostavni dio naše svakodnevnice. Osim navedenih funkcija na pametnim telefonima, te igranja igara, tu su pametni satovi koji koriste UI za praćenje zdravstvenih parametara, poput otkucaja srca i kvalitete sna, pružajući korisnicima uvid u njihovo zdravlje u stvarnom vremenu. UI igra ključnu ulogu u modernoj upotrebi Interneta i e-mail komunikacije, gdje se koristi za filtriranje neželjene pošte, personalizaciju sadržaja i poboljšanje sigurnosti. U automobilskoj industriji doprinosi razvoju autonomnih vozila, poboljšava sustave pomoći vozačima i optimizira upravljanje prometom. U području medicine pomaže u dijagnostici, liječenju i upravljanju zdravstvenim informacijama. Pronalazi široku primjenu u gotovo svakom industrijskom sektoru, gdje značajno doprinosi efikasnosti, razvoju inovacija i automatizaciji procesa rada.
Zamislimo neki objekt koji nam je svima poznat, npr. stolica, i pokušajte si zamisliti u kojim se sve varijantama pojavljuje. Dakle, čovjek je izložen velikom broju informacija iz svijeta koji nas okružuje, čime konstantno dobiva iskustvo i nova znanja. Čovjek ima sposobnost razmišljati subjektivno i intuitivno, u situacijama kada je pojavu ili objekt gotovo nemoguće opisati na formalan način. Brojni dosadašnji pokušaji da se svijet oko nas opiše strogo formalnim jezikom kako bi računalni sustav mogao u njemu biti uspješan nisu dali zadovoljavajuće rezultate. Računalni sustavi iz područja umjetne inteligencije najčešće su sposobni raditi jednu ili nekoliko stvari vrlo dobro, ali zaostaju u implementaciji učenja iz iskustva koje dobivaju iz svijeta oko sebe. Razvoj velikih jezičnih modela, tzv. LLM (engl. Large Language Model) poput ChatGPT
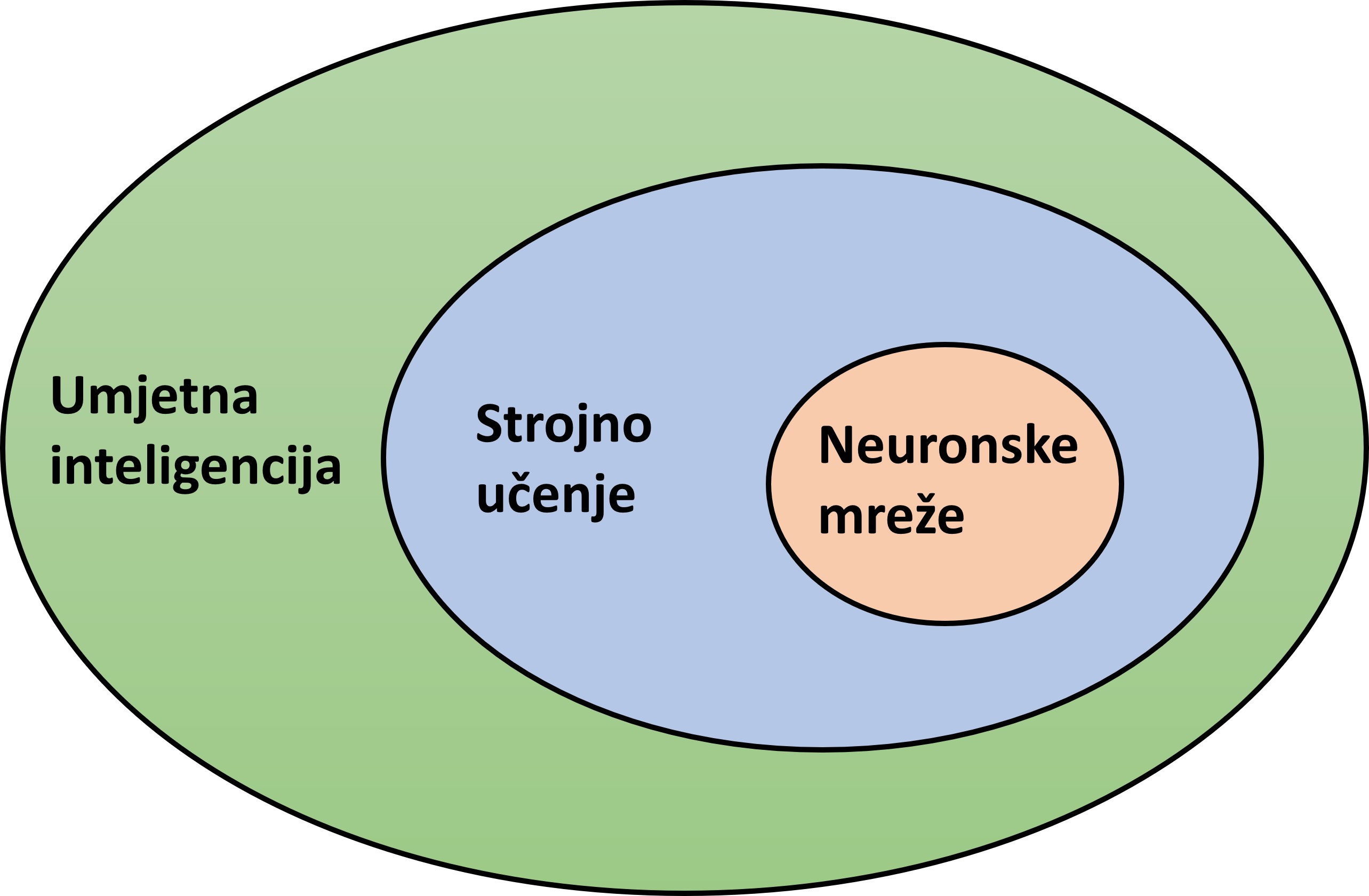
Dakle, umjetna inteligencija je računalni sustav koji može obavljati zadatke koji inače zahtijevaju ljudsku inteligenciju, kao što su vizualna percepcija, prepoznavanje govora, donošenje odluka i prevođenje s jednog jezika na drugi. Strojno učenje je grana umjetne inteligencije. Najvažnija značajka leži u sposobnosti učenja kada je izložena velikim količinama podataka, bez ljudske intervencije i programiranja. Učenje najčešće podrazumijeva da algoritmi strojnog učenja pokušavaju minimizirati zadanu pogrešku ili maksimizirati vjerojatnost točnog predviđanja. Obično su početna predviđanja pogrešna, stoga izmjerimo koliko su predviđanja pogrešna suprotstavljajući ih pravim ili očekivanim vrijednostima, a zatim upotrijebimo tu pogrešku da modificiramo sustav umjetne inteligencije. Neuronske mreže su alat strojnog učenja, a onda i umjetne inteligencije, što je ilustrirano na slici
2Neuronske mreže
Neuronske mreže su računalni sustavi koji su inspirirani biološkim neuronskim mrežama koje čine životinjski mozak. Sastoje se od slojeva, a slojevi od neurona. Slojevi neuronske mreže su povezani jedni s drugima, te počinju ulaznim slojem koji prima podatke i šalje ih u skrivene slojeve. U skrivenim slojevima se podaci obrađuju i šalju u neurone izlaznog sloja koji daje izlaz neuronske mreže. Neka je N_{L} broj slojeva neuronske mreže. Ako je N_{L} \geq 3, pri čemu ulazni sloj ne ubrajamo, mrežu zovemo dubokom, a inače ju zovemo plitkom. Glavno obilježje neuronskih mreža je sposobnost učenja na temelju ulaznih podataka. Uobičajeno se većina skupa podataka koristi za učenje, dok se ostatak upotrebljava za testiranje sposobnosti generaliziranja - npr., 90% podataka koristi se za treniranje neuronske mreže, a preostalih 10% za testiranje. Jedan prolazak algoritma kroz podatke za treniranje (učenje) nazivamo epoha.
Neuronske mreže su iznimno prilagodljive, pomažu nam grupirati neobilježene podatke prema sličnosti na temelju ulaznih podataka, napraviti predviđanja i/ili klasificirati podatke na temelju skupa podataka za treniranje. Postoje brojne vrste neuronskih mreža, koje se razlikuju prema arhitekturi, načinu učenja i sl. Najčešće vrste neuronskih mreža su umjetne, povratne i konvolucijske. Princip učenja zasniva im se na sličnim matematičkim načelima. Imaju ulaze na temelju kojih kroz slojeve trebaju stvoriti smisleni izlaz koji su "naučile" minimizirajući funkciju gubitka. Svaki neuron posjeduje težinu w koja se propagira na sljedeći sloj kroz aktivacijsku funkciju i na taj način se dobivaju izlazi. Detaljnije o tome može se pronaći na web stranicama
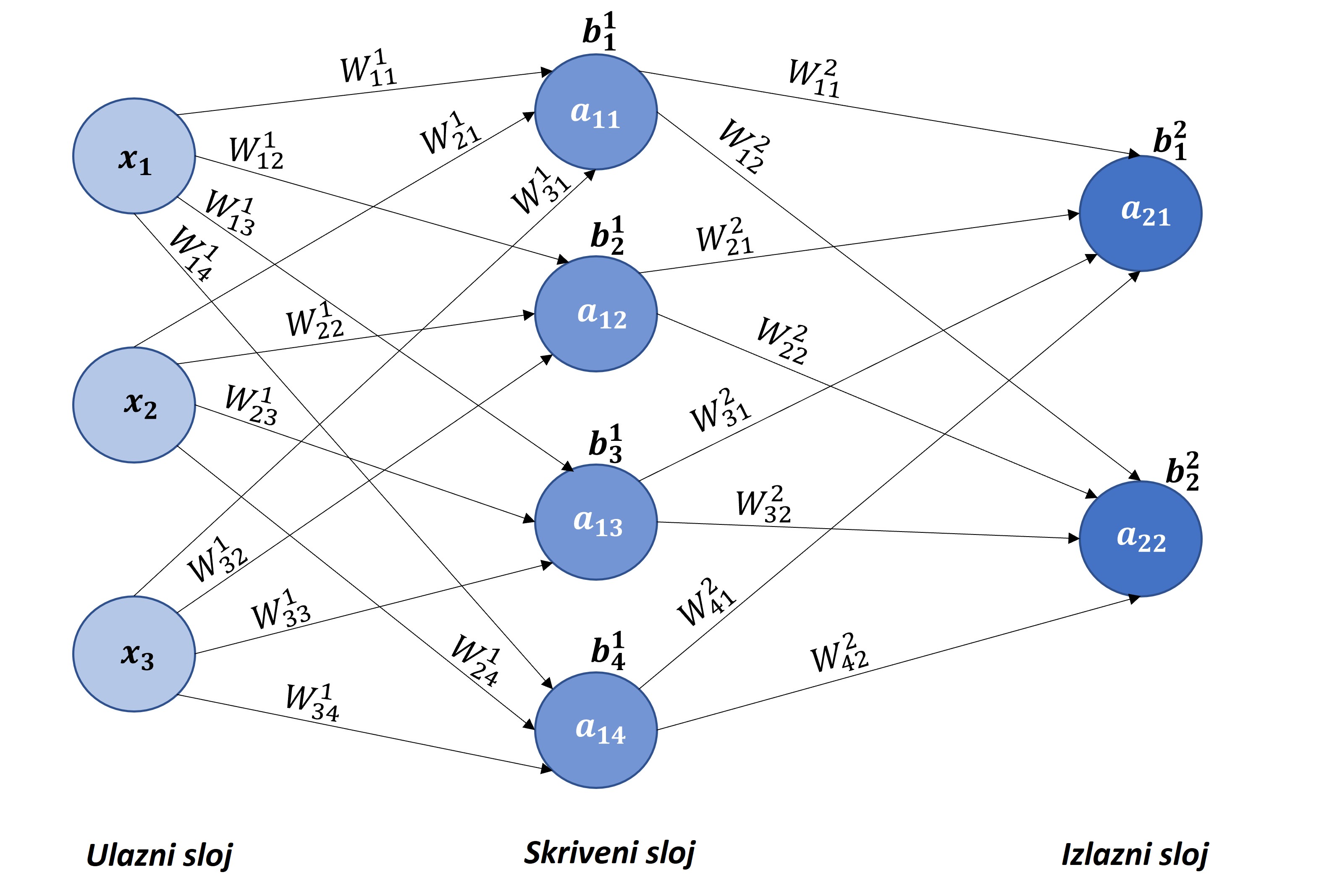
Ulazi imaju oznake x_{p}, p= 1, ..., n, težine W_{ij}^{k} \in \mathbb{R}, gdje je i redni broj neurona prethodnog sloja, j redni broj neurona trenutnog sloja, k redni broj trenutnog sloja, b_{j}^{k} \in \mathbb{R}, a vrijednost izraza a_{kj} se dobiva po formuli:
\begin{align} a_{kj} &= \sigma \left(\sum_{i} W_{ij}^{k} x_{i} + b_{j}^{k} \right); k = 1\\ a_{kj} &= \sigma \left(\sum_{i} W_{ij}^{k} a_{i ,k-1} + b_{j}^{k}\right); k = 2, 3, ..., N_{L} \end{align}
Funkcija \sigma se naziva aktivacijska funkcija i koristi se kako bi neuronska mreža mogla uspješno učiti nelinearna preslikavanja. Aktivacijska funkcija djeluje po komponentama ulaznog vektora. Izbor te funkcije vrlo je važan dio konstruiranja neuronske mreže, jer o njenom odabiru ovisi brzina učenja i performanse same neuronske mreže. Najčešće upotrebljavane aktivacijske funkcije su: sigmoid \sigma (x)= \frac{1}{1+e^{-x}}, tangens hiperbolni \sigma (x)= tanh(x), ReLU \sigma (x)= max(0,x) i Leaky ReLU \sigma (x)= max(\alpha x,x), gdje je \alpha\in \mathbb{R} najčešće pozitivna konstanta manja od jedan. Dublje mreže zapisujemo kao kompoziciju funkcija, te se tada za y \in \mathbb{R}^{d} neuronska mreža zapisuje kao kompozicija
(1)
NM(y) = C_{N_{L}} \circ \sigma \circ C_{N_{L}-1} \circ \sigma \circ ... \sigma \circ C_{2} \circ \sigma \circ C_{1} (y),
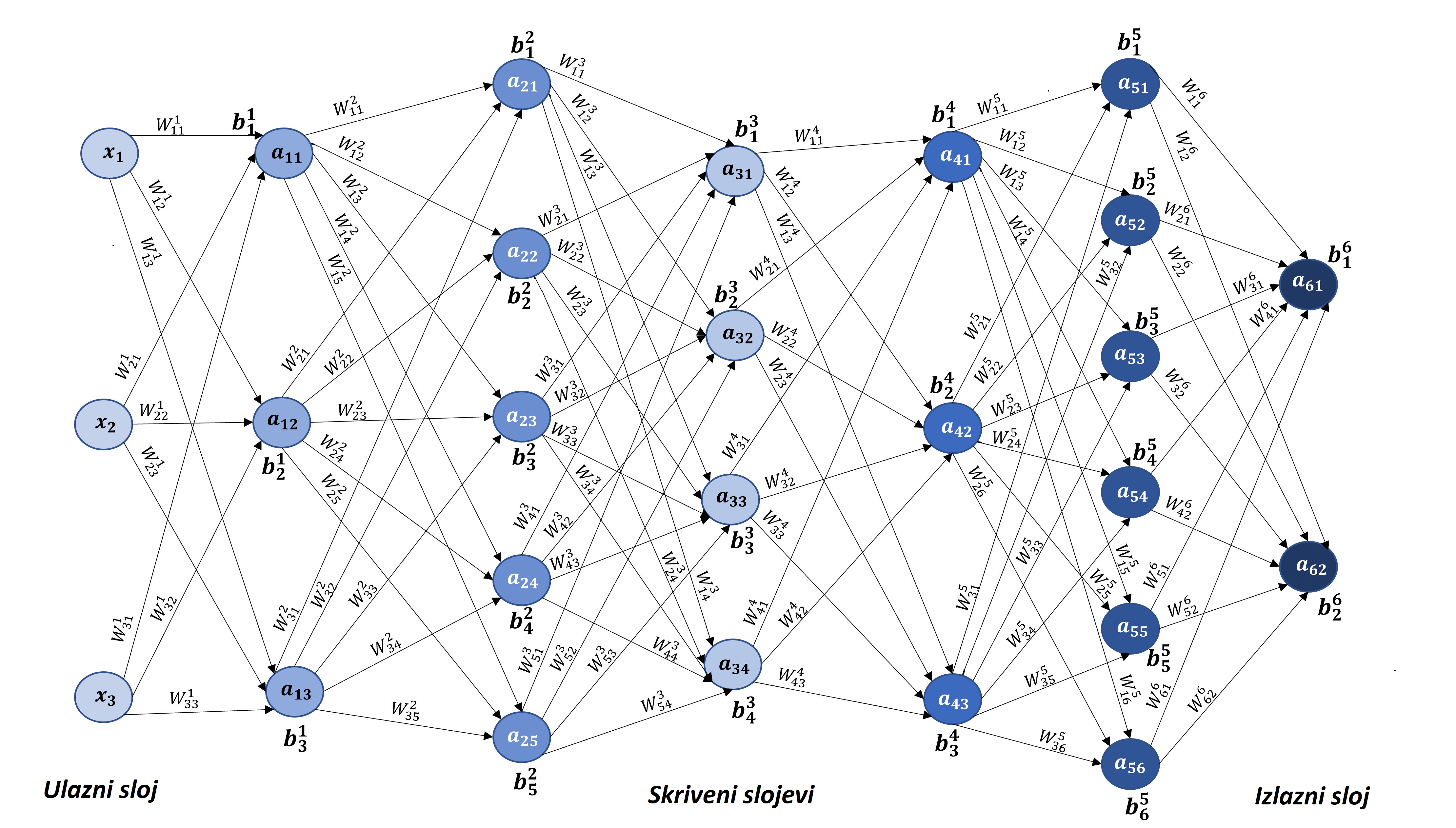
pri čemu je za 1 \le k \le K, C_{k}(z_{k})=W_{k} z_{k} + b_{k}, W_{k} \in \mathbb{R}^{d_{k+1} \times d_{k}}, z_{k} \in \mathbb{R}^{d_{k}}, b_{k} \in \mathbb{R}^{d_{k+1}}. Grafički prikaz neuronske mreže koja sadrži pet skrivenih slojeva dan je na slici
Broj parametara za treniranje se računa po pravilu
(2)
N_{param} = \sum_{k=1}^{L} N_{k} N_{k-1} + N_{k},
gdje je L broj slojeva neuronske mreže, N_{k} broj neurona u k-tom sloju. Tada neuronska mreža sa slike
| \bullet | ulazni sloj \rightarrow prvi skriveni sloj: 3\cdot3 + 3 = 12 parametara |
| \bullet | prvi skriveni sloj \rightarrow drugi skriveni sloj: 5\cdot3 + 5=20 parametara |
| \bullet | drugi skriveni sloj \rightarrow treći skriveni sloj: 4\cdot5 + 4 = 24 parametra |
| \bullet | treći skriveni sloj \rightarrow četvrti skriveni sloj: 3\cdot4 + 3 = 15 parametara |
| \bullet | četvrti skriveni sloj \rightarrow peti skriveni sloj: 6\cdot3 + 6 = 24 parametra |
| \bullet | peti skriveni sloj \rightarrow izlazni sloj: 2\cdot6 + 2 = 14 parametara. |
Ukupno, navedena arhitektura neuronske mreže sadrži 109 parametara za treniranje.
Univerzalni teorem aproksimacije implicira da su neuronske mreže univerzalni aproksimatori, odnosno da je bilo koju neprekidnu funkciju moguće aproksimirati neuronskom mrežom proizvoljno točno, uz određene uvjete. Teorem daje garanciju da takva neuronska mreža postoji, ali ne puno više od toga, odnosno ne daje informacije o odabiru hiperparametara neuronske mreže.
Teorem 1.[Univerzalni aproksimacijski teorem] Neka je \sigma ograničena, monotono rastuća neprekidna funkcija, različita od konstante. Neka je l_{m} m-dimenzionalna kocka [0,1]^{m} i neka neprekidne funkcije na I_{m} imaju oznaku C(I_{m}). Tada za bilo koju funkciju f \in C(I_{m}) i \epsilon \gt 0 postoji prirodni broj N, realne konstante v_{i} , b_{i} \in \mathbb{R} i realni vektor w_{i} \in \mathbb{R}^{m} , i=1,2,... N, tako da je dobro definirana funkcija
koja predstavlja aproksimaciju funkcije f, a funkcija f je neovisna o q, tj.,
za sve x \in I_{m}. Drugim riječima funkcije oblika F(x) su guste u I_{m}.
(3)
F(x) = \sum_{i=1}^{N}v_{i} q (w_{i}^{T} x + b_{i}),
(4)
|F(x)-f(x)|\lt \epsilon
Dvije najraširenije vrste strojnog učenja su nadzirano učenje i nenadzirano učenje. U nadziranom učenju poznati su ulazni i očekivani izlazni podaci, dok kod nenadziranog učenja poznati su samo ulazni podaci. Za učenje neuronske mreže potrebno je odabrati jedan od optimizacijskih algoritama za učenje poput stohastičkog gradijentnog spusta, Adagrada, Adadelta, Adam, Nadam, RMSprop, AdaMax i slično. Funkcija koja računa pogrešku između željenih i dobivenih izlaznih vrijednosti naziva se funkcija gubitka. Funkcija gubitka definira se izrazom:
(5)
J(W,b) := \frac{1}{n} \sum_{i=1}^{N} \mathcal{L} (\hat{y_{i}}, y_{i}),
gdje \hat{y} predstavlja izlaz neuronske mreže, y je prava vrijednost, a \mathcal{L} je funkcija koji mjeri pogrešku na jednom primjeru trening skupa. Dakle, funkcija gubitka mjeri pogrešku neuronske mreže na skupu podataka za treniranje. Najčešći primjeri funkcija za mjerenje pogreške su prosječna kvadratna pogreška MSE= \frac{1}{n} \sum_{i=1}^{n} (\hat{y_{i}} - y_{i})^{2}, prosječna apsolutna pogreška MAE=\frac{1}{n} \sum_{i=1}^{n} |\hat{y_{i}} - y_{i}| i prosječna apsolutna postotna pogreška MAPE=\frac{100\% }{n} \sum_{i=1}^{n} \frac{|\hat{y_{i}} - y_{i}|}{|y_{i}|}.
Gradijent je vektorsko polje čije su komponente parcijalne derivacije funkcije. Gradijent određuje nagib tangente grafa funkcije, odnosno gradijent pokazuje smjer gdje je najveće povećanje funkcije. Gradijent mjeri koliko se izlaz funkcije promijeni ako se malo promjene ulazi. Nakon izračunate funkcije gubitka, računamo gradijent funkcije gubitka s obzirom na svaki parametar neuronske mreže. U neuronskim mrežama gradijent nam pomaže odrediti smjer i veličinu u kojemu trebamo mijenjati svaki parametar neuronske mreže kako bismo dostigli minimum funkcije gubitka. Kada neuronskoj mreži predajemo podatke u ulazni sloj koji se tada unaprijed šalju u skrivene slojeve sve do izlaznog sloja nazivamo forward propagation. Tijekom treniranja pomoću forward propagation računamo vrijednost funkcije gubitka. Back propagation (BP) algoritam informaciju o vrijednosti funkcije gubitka šalje od izlaznog sloja unazad sve do ulaznog sloja kako bi izračunao gradijent funkcije gubitka u odnosu na svaki parametar neuronske mreže, koristeći pravilo derivacije složene funkcije. Prema tom pravilu računa gradijent funkcije gubitka u odnosu na svaki parametar, računajući gradijent jedan po jedan sloj, ponavljajući unatrag od izlaznog sloja kako bi se izbjeglo suvišno izračunavanje međučlanova. Više se može pronaći u
Metoda stohastičkog gradijentnog spusta pomoću funkcije gubitka i gradijenta uči neuronsku mrežu traženo preslikavanje. Ona je iterativni algoritam za traženje točke lokalnog minimuma neprekidno diferencijabilne funkcije f: \mathbb{R}^{n} \rightarrow \mathbb{R} i oblika je:
(6)
x^{(k+1)}=x^{(k)}+ \alpha_{k} p^{(k)}, k=0,1,...
gdje je x^{(0)} početna aproksimacija, \alpha_{k} \gt 0 duljina koraka u smjeru vektora smjera kretanja p^{(k)}=-\nabla f(x^{(k)}), a \nabla f(x^{(k)}) gradijent funkcije f u točki x^{(k)}. Detaljnije o algoritmima se može pročitati u
Stopa učenja je skalar koji će odrediti duljinu koraka prema minimumu funkcije. Taj parametar ne smije biti ni prevelik ni premalen za učenje neuronske mreže i ovisi o problemu koji se rješava. Ako je stopa učenja prevelika, algoritam će premašiti cilj i možda neće dosegnuti do minimuma, a ako je premala, proces učenja će trajati predugo.
Prilikom učenja neuronskih mreža često dolazi do problema overfita, odnosno prevelikog prilagođavanja trening skupu. Moguće je na trening skupu dobiti gotovo 100% točnost predviđanja, a na test skupu samo 60%, tj. kažemo da neuronska mreža nema dovoljno dobro svojstvo generalizacije. Problem overfita se nastoji ukloniti metodama regularizacije. Najčešće korištene su L_{1} i L_{2} regularizacija, dodavanje dropout slojeva i dodavanje regularizacijskog izraza na funkciju gubitka. U slučaju prevelikog broj parametara za učenje s obzirom na broj ulaznih podataka može doći do problema underfita, gdje neuronska mreža ne može učiti efikasno iz trening skupa niti na njemu samom. Tada je najčešće potrebno mijenjati arhitekturu neuronske mreže i/ili promijeniti skup ulaznih podataka.
3Numerički eksperimenti
Za numeričke eksperimente koristili smo Python 3 i prikladne pakete. Najvažniji korišteni paketi su Tensorflow 2
3.1Periodička funkcija f(x)=\sin(x), x\in \mathbb{R}
Prvi numerički eksperiment je periodička funkcija jedne varijable f(x) = \sin(x). Neuronsku mrežu ćemo trenirat na uniformnoj mreži čvorova osnovnog perioda, a analizirati rješenja na drugom skupu čvorova u osnovnom periodu, kao i problem ekstrapolacije. Također, izračunati ćemo relativnu pogrešku u L_{2} normi. Na slici
U tablici
Tablica 1: Tablica rezultata testova prilikom treniranja neuronske mreže jedne varijable. Kazalo: n = naziv testa; ss = broj skrivenih slojeva; ne = broj neurona u sloju; p = broj parametara za treniranje; epoha = broj prolazaka kroz podatke; loss = vrijednost funkcije gubitka nakon zadnje epohe; L_{2} rel. od = relativna pogreška aproksimacije u L_{2} normi na osnovnoj domeni; L_{2} rel. e = relativna pogreška aproksimacije u L_{2} normi za ektrapolaciju na segmentu [-1000,1000].
| \cline{1-9} n | ss | ne | p | epoha | up | loss | {L_{2} rel. od} | {L_{2} rel. e} |
| \cline{1-9} t1 | 2 | 20 | 481 | 2e4 | 100 | 1.5e-7 | 5.19e-4 | 5.22e-4 |
| t2 | 2 | 10 | 141 | 2e4 | 100 | 7.8e-7 | 1.19e-3 | 1.17e-3 |
| t3 | 2 | 10 | 141 | 2e4 | 100 | 2.2e-6 | 1.90e-3 | 1.93e-3 |
| t4 | 2 | 10 | 141 | 2e4 | 500 | 7.4e-7 | 1.21e-3 | 1.22e-3 |
| t5 | 2 | 20 | 481 | 2e4 | 100 | 2.7e-7 | 7.09e-4 | 7.18e-4 |
| t6 | 2 | 20 | 481 | 2e4 | 500 | 1.3e-7 | 4.83e-4 | 4.96e-4 |
| t7 | 2 | 20 | 481 | 5e4 | 500 | 6.6e-8 | 3.56e-4 | 3.40e-4 |
| t8 | 2 | 50 | 2701 | 2e4 | 100 | 5.8e-8 | 3.09e-4 | 2.99e-4 |
| t9 | 5 | 5 | 136 | 1e4 | 200 | 4.2e-7 | 8.50e-4 | 8.47e-4 |
| t10 | 6 | 5 | 166 | 2e4 | 100 | 5.1e-7 | 9.37e-4 | 9.38e-4 |
| r1 | 2 | 50 | 2701 | 2e4 | 100 | 5.0e-6 | 3.30e-3 | 3.34e-3 |
| \cline{1-9} |
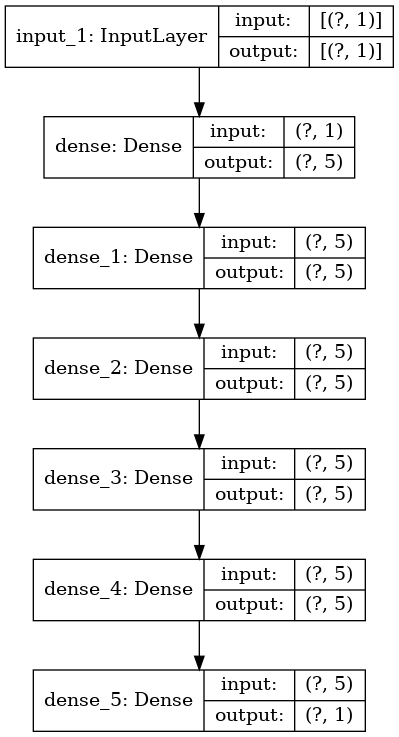
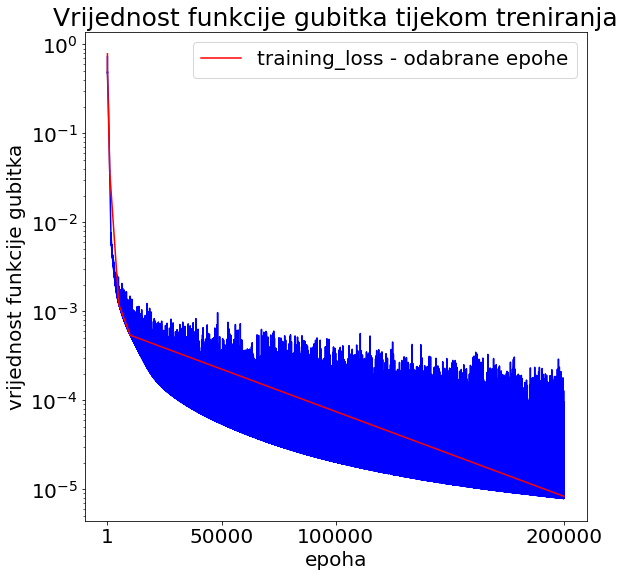
Naredna analiza, slike i grafovi odnositi će se na neuronsku mrežu testa t10 iz tablice čija je arhitektura prikazana na slici
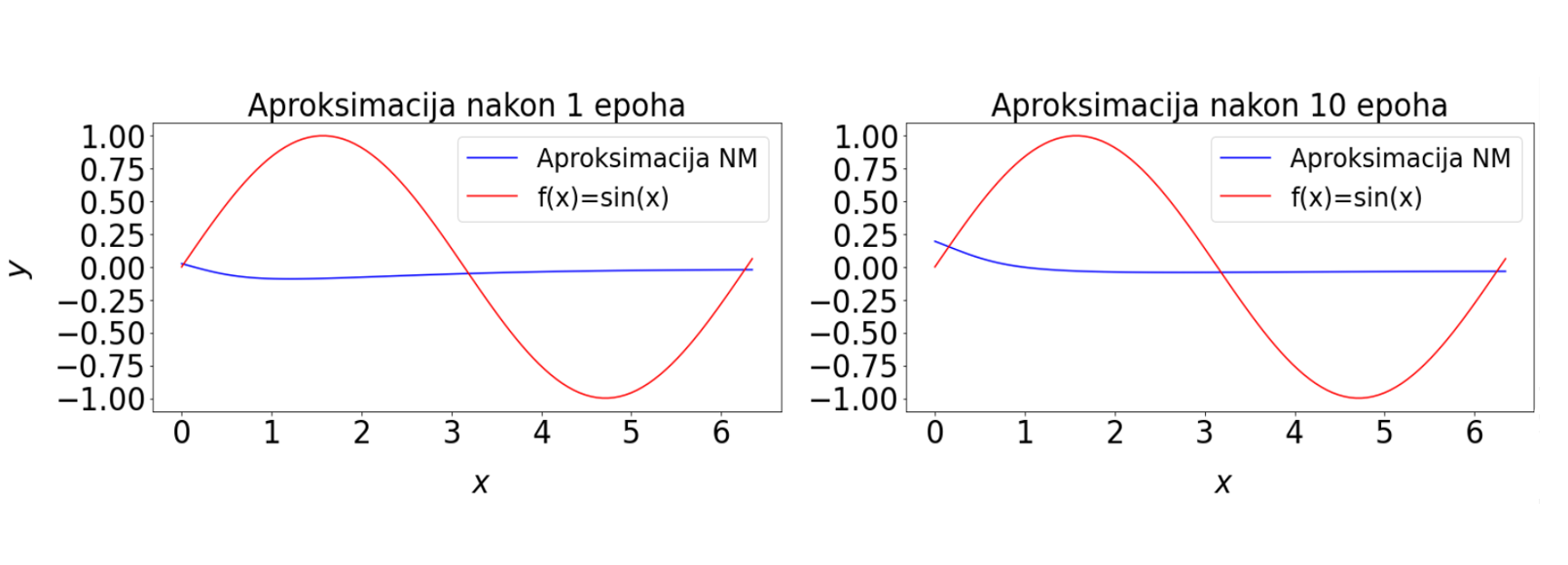
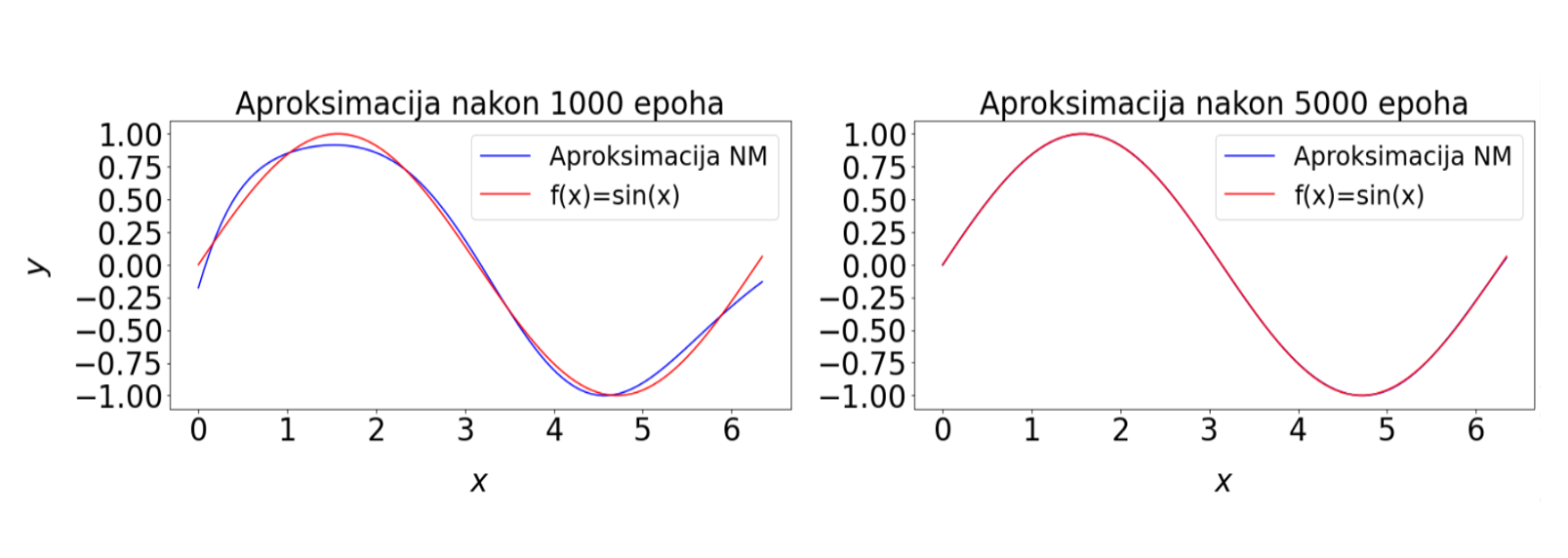
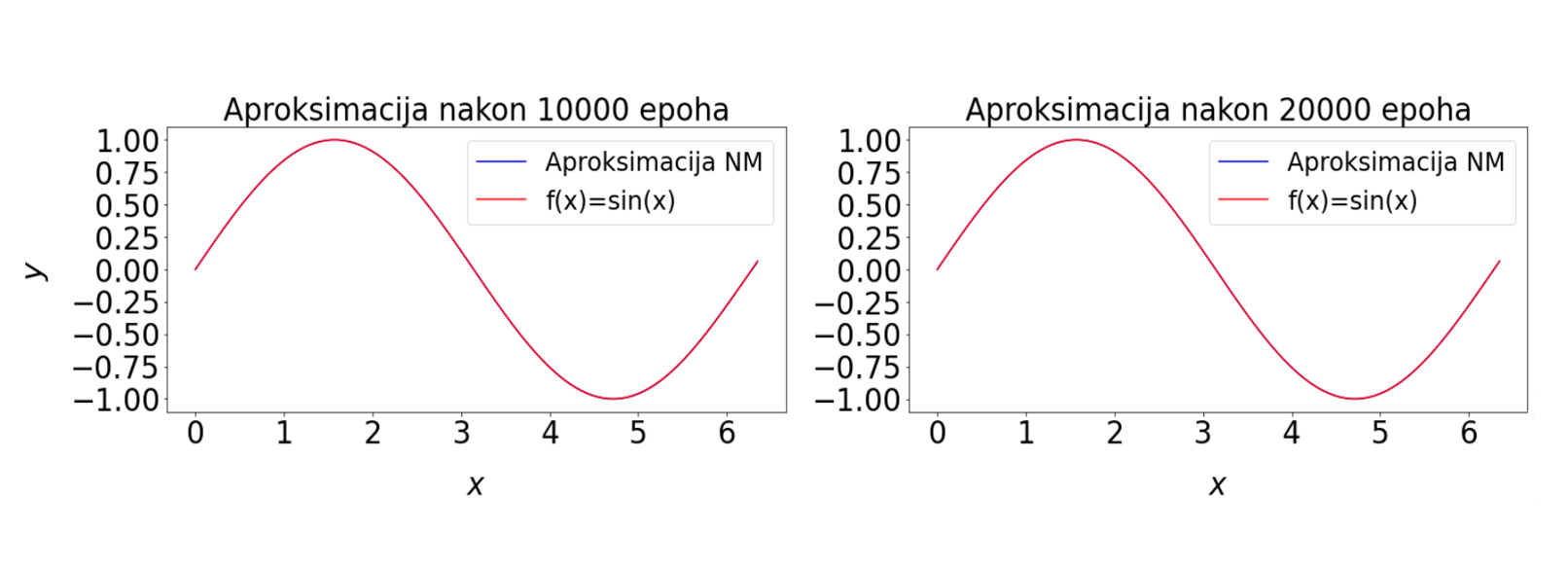
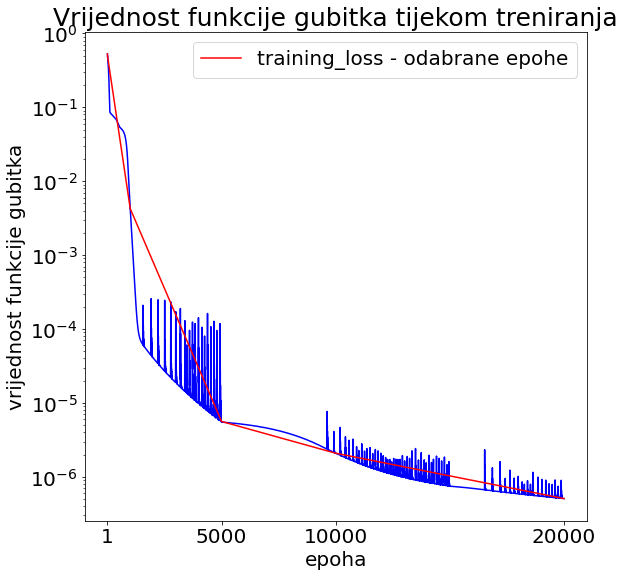
Slika 6: Vrijednost funkcije gubitka tijekom treniranja funkcije jedne varijable. Plava krivulja prikazuje vrijednost funkcije gubitka po svim epohama, dok crvena u odabranim - epohama u kojima crtamo trenutne aproksimacije. Veće oscilacije vrijednosti funkcije gubitka ukazuju da je stopa učenja prevelika. Zato koristimo Keras callback metodu koja omogućava da se stopa učenja mijenja tijekom treniranja prema zadanim uvjetima.
Test 1
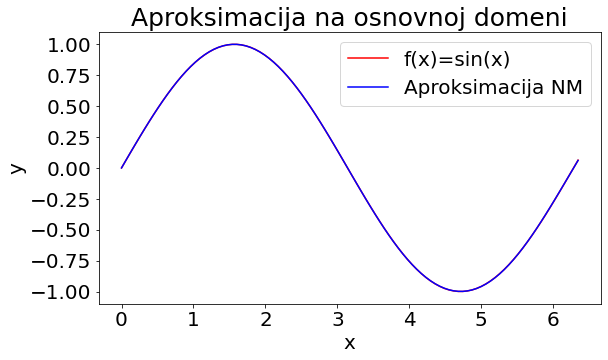
Provesti ćemo testiranje neuronske mreže na drugačijem skupu točaka od onih sa kojima je trenirala, ali su ulazni podaci iz iste domene. Računamo funkciju gubitka i uočavamo da je reda 10^{-7}, odnosno da je prosječna razlika između željenih i dobivenih izlaznih vrijednosti na razini jednostruke preciznosti realnih brojeva na računalu. Grafički prikaz na slici
x_{(a, b)} = 0.5(x_{(-1, 1)} + 1)\cdot(b - a) + a.
Formula Gausove integracije u jednoj dimenziji je dana izrazom:
\int_{a}^{b} f(x)dx \approx \sum_{i = 1}^{n} w_{i} f(x_{i}).
Test 2
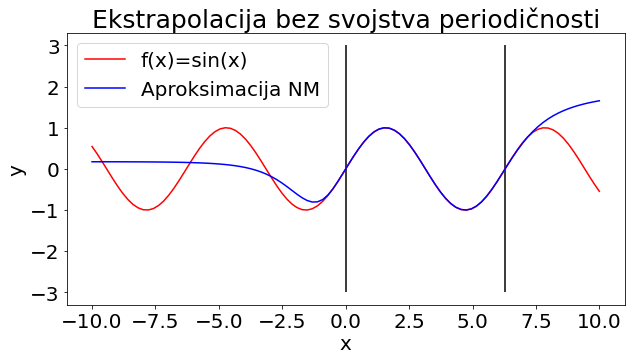
U drugom testiranju neuronskoj mreži su dane različite točke od onih sa kojima je trenirala, ali i proširena domena ulaznih podataka na segment [-10,10]. Vrijednost funkcije gubitka sada iznosi 0.37, što je nekoliko redova veličine veće od rezultata na osnovnoj domeni. Analizom grafičkog prikaza
Test 3
Pokušat ćemo popraviti rezultate prethodnog testa tako da ulazne podatke premjestimo u osnovni period, a zatim provodimo treće testiranje s novim ulaznim podacima. Za funkciju gubitka dobivamo vrijednost od 4.45\cdot 10^{-7}, što je veliko poboljšanje u odnosu na vrijednost funkcije gubitka iz drugog testiranja. Analizom grafičkog prikaza
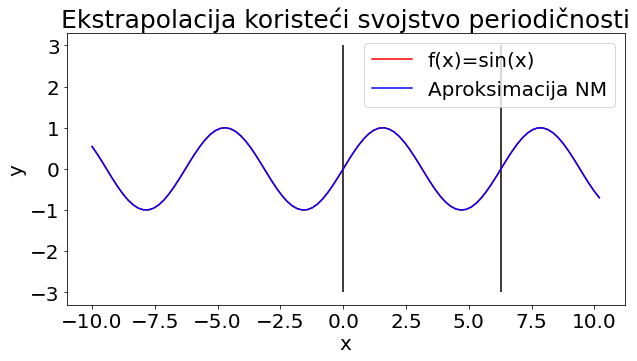
Dodatnu provjeru radimo izračunom relativne L_{2} pogreške na segmentu [-1000,1000]. Za pogrešku dobivamo vrijednost 9.38\cdot 10^{-4}, što je vrlo zadovoljavajući rezultat budući da smo značajno proširili segment na kojem računamo pogrešku u odnosu na segment na kojem je neuronska mreža trenirana.
3.22D primjer: f(x, y)=\sin\left(\sqrt{x^{2}+y^{2}}\right), x, y \in [-6, 6]
Testirat ćemo učenje neuronske mreže na primjeru funkcije s dvije varijable:
f(x, y)=\sin\left(\sqrt{x^{2}+y^{2}}\right), x, y \in [-6, 6].
Za analizu i grafički prikaz dobivenih rješenja koristit ćemo paket FEniCS
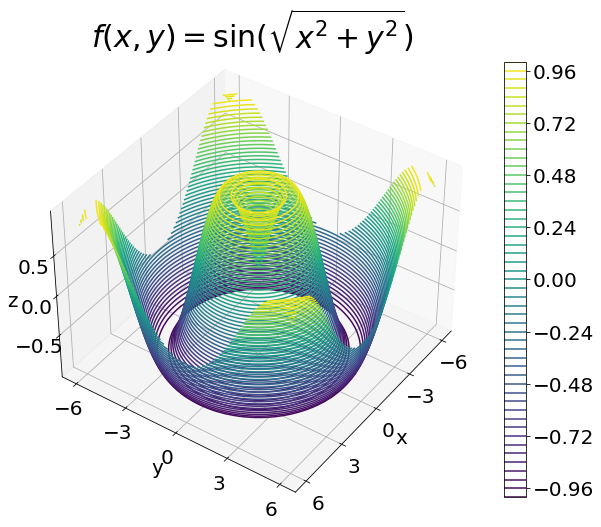

Ponovno ćemo testirati različite arhitekture i hiperparametre neuronske mreže i gledati funkciju gubitka, kao i relativnu pogrešku u L_{2} normi. Funkcija f(x, y) ima bogatu strukturu i promatrat ćemo aproksimaciju neuronskom mrežom kroz epohe treniranja. Čvorove i vrijednosti funkcije za treniranje generirat ćemo na uniformnoj mreži, a zatim će se za izračun relativne L_{2} norme koristiti čvorovi mesha FEniCS paketa - to je ujedno i test neuronske mreže koja ovdje treba aproksimirati funkciju f(x, y) u različitim točkama od onih u kojima je trenirala. Primjer Tensorflow grafa arhitekture neuronske mreže dan je na slici
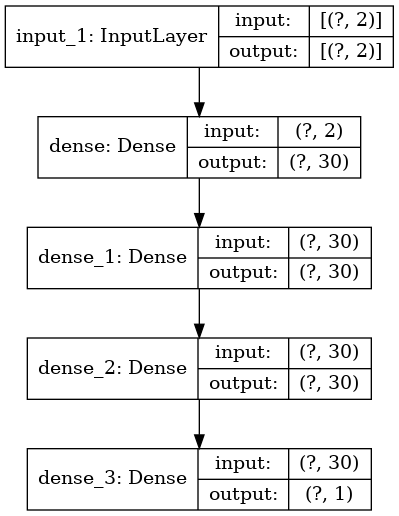
U tablici
Tablica 2: Tablica rezultata nekih testiranja za funkciju dvije varijable. Funkcija gubitka je MSE, optimizacijska metoda Adam za sve test primjere. Oznaka test primjera vezana je i uz aktivacijsku funkciju: t = tanh. Kazalo: ss = broj skrivenih slojeva; ne = broj neurona u sloju; p = broj parametara za treniranje; epoha = broj epoha treniranja; lr = stopa učenja; h = udaljenost između ekvidistantnih čvorova; loss = vrijednost funkcije gubitka nakon zadnje epohe; L_{2} rel. = relativna pogreška aproksimacije u L_{2} normi s obzirom na FEniCS. Keras callback za stopu učenja: 1e-3 za epohe do 5000, 1e-4 za epohe [5000, 14999], 5e-5 inače.
| \cline{1-9} # | ss | ne | p | epoha | lr | h | loss | {L_{2} rel.} |
| \cline{1-9} t1 | 2 | 100 | 10501 | 1e5 | 2e-4 | 0.03 | 1.24e-5 | 5e-3 |
| t2 | 4 | 50 | 7851 | 1e5 | 2e-4 | 0.05 | 7.7e-6 | 3.9e-3 |
| t3 | 2 | 30 | 1051 | 2e5 | 2e-4 | 0.05 | 5.77e-6 | 3.3e-3 |
| t4 | 3 | 30 | 1981 | 2e5 | callback | 0.05 | 6.17e-6 | 3.4e-3 |
| t5 | 2 | 30 | 1051 | 2e5 | callback | 0.2 | 3.85e-5 | 7.8e-3 |
| t6 | 2 | 10 | 151 | 2e5 | callback | 0.2 | 9.9e-4 | 4.3e-2 |
| t7 | 2 | 10 | 151 | 2e5 | callback | 0.05 | 8.2e-4 | 4.0e-2 |
| t8 | 6 | 10 | 591 | 2e5 | callback | 0.05 | 1.7e-4 | 1.8e-2 |
| t9 | 10 | 10 | 1031 | 2e5 | callback | 0.05 | 3.07e-5 | 7.3e-3 |
| t10 | 15 | 10 | 1581 | 2e5 | callback | 0.05 | 1.53e-5 | 4.9e-3 |
| \cline{1-9} |
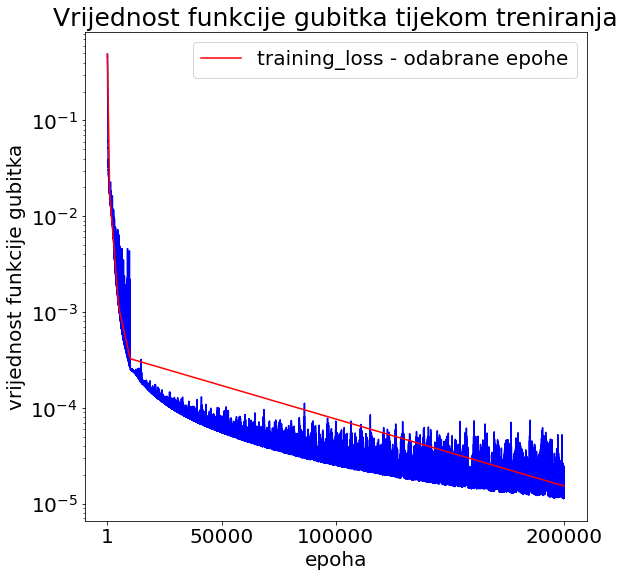
Na slici
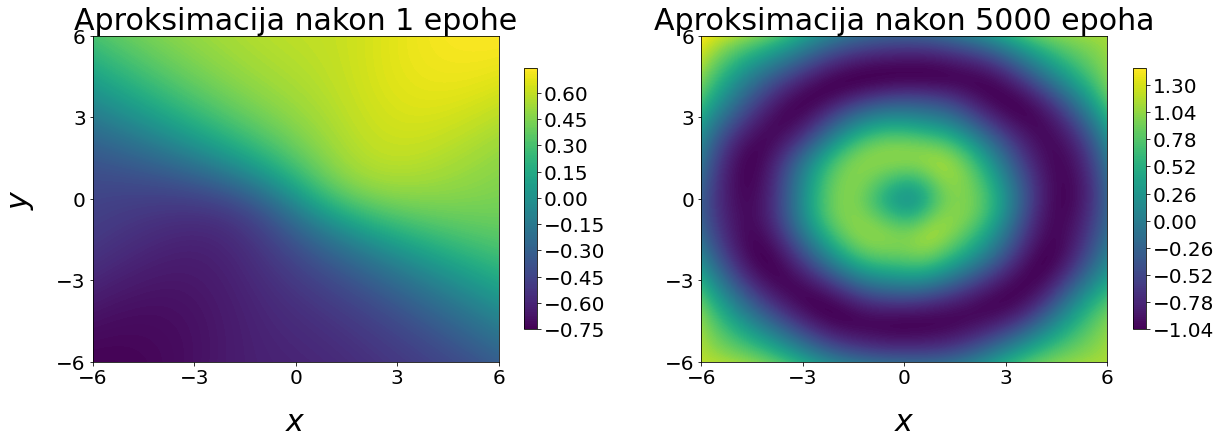
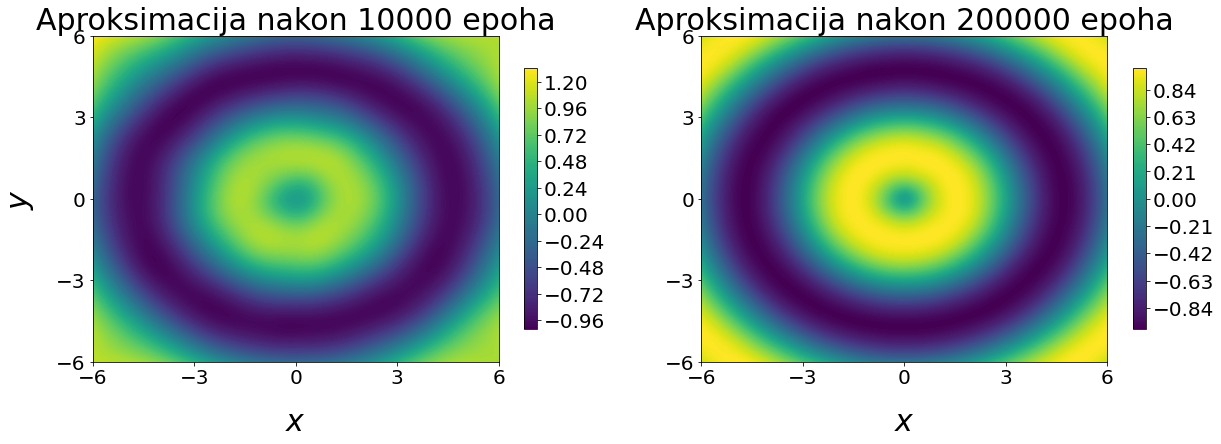
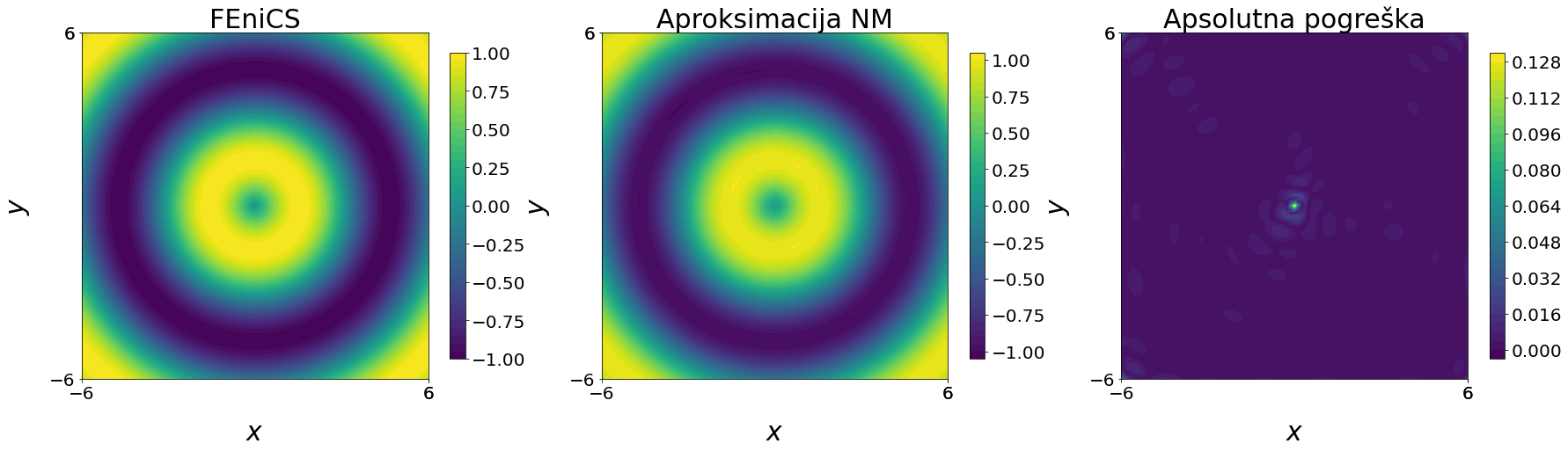
4Zaključak
U ovom radu prezentirana je osnovna teorija neuronskih mreža kao aproksimatora te numerički eksperimenti učenja funkcija jedne i dviju varijabli. Proces aproksimacije pomoću neuronske mreže grafički je prikazan tijekom različitih epoha treniranja. Ova vizualna reprezentacija ključna je za demonstriranje postupka učenja neuronske mreže, koja u svojim početnim fazama ne odražava ciljanu funkciju. Numerički eksperimenti za primjer funkcije f(x)= \sin(x) ukazuju da razne arhitekture neuronske mreže vode do pogreške istog reda koristeći MSE funkciju gubitka i relativnu L_{2} pogrešku koristeći Gaussovu integraciju. Demonstriran je problem ekstrapolacije periodičke funkcije, koji je ovdje moguće uspješno riješiti korištenjem periodičnosti funkcije. U dvije dimenzije, na primjeru funkcije f(x, y)=\sin\left(\sqrt{x^{2}+y^{2}}\right), x, y \in [-6, 6], prezentirani su numerički eksperimenti. Problem dvije varijable je kompliciraniji i potrebno je značajno više čvorova, a onda i vremena za treniranje neuronske mreže. Osim standardne funkcije gubitka MSE, kao mjeru točnosti gledamo relativnu pogrešku u L_{2} normi s obzirom na rješenje dobiveno pomoću paketa FEniCS, koji u sebi sadrži funkcije za takve operacije. Nekoliko numeričkih eksperimenta je objavljeno na GitHub platformi i mogu služiti za učenje i rad s Tensorflow 2 paketom, kao i elementima analize točnosti aproksimacije neuronske mreže.{}
Bibliografija
| [1] | Abadi, Martin, Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., … i ostali: Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) (pp. 265–283), 2016. |
| [2] | Goodfellow, Ian J.; Bengio, Yoshua; Courville, Aaron: Deep Learning, MIT Press, 2016., http://www.deeplearningbook.org |
| [3] | Langtangen, H. P.; Logg, A.: Solving PDEs in Python, Springer, 2017. |
| [4] | Pathmind: https://wiki.pathmind.com/ai-vs-machine-learning-vs-deep-learning (pristupljeno 04.05.2022.) |
| [5] | Towards Data Science: https://towardsdatascience.com/a-beginners-guide-to-neural-networks-d5cf7e369a13 (pristupljeno 04.05.2022.) |
| [6] | Towards Data Science: https://towardsdatascience.com/understanding-neural-networks-19020b758230 (pristupljeno 04.05.2022.) |
| [7] |
ChatGPT, OpenAI, 31.3.2023. https://chat.openai.com. |